


Leur côté massif, instantané et en continu nourrit de nombreux espoirs : disposer de données fines au moment et à l’endroit voulu, et mesurer des évolutions spatiales ou temporelles.
Cet article propose un tour d’horizon des cas d’usage de ces données massives pour la connaissance des mobilités, mettant en avant leur complémentarité avec les autres sources de données et les questions qui restent encore ouvertes à notre connaissance.
Les principes du recueil de données, informations fournies et traitement des données, pour chaque source de données, sont plus largement présentés dans la série de fiches Cerema "les données de mobilité pour la modélisation des déplacements". Les données FCD font l’objet de rapports plus détaillés du Cerema.
Données de localisation/positionnement des véhicules (Floating Car data, FCD) :
 Il s’agit de données/traces de véhicules connectés.
Il s’agit de données/traces de véhicules connectés.
La méthode de mesure par véhicule flottant est ancienne, et déjà définie par le Setra dans les années 80 : "Technique de mesure des conditions de circulation (temps de parcours) qui consiste à circuler normalement sur le réseau en s'insérant dans la circulation ordinaire et en dépassant sur l'ensemble du parcours autant de fois qu'on a été soi-même dépassé". Le terme est resté quand sont apparus des systèmes ("boîtiers télématiques") permettant de géolocaliser les véhicules en temps réel et fournir des données bien plus riches que le seul temps de parcours.
Le taux d’équipement des voitures a augmenté vers les années 2010 et a décollé avec l’entrée en vigueur en 2018 du règlement européen sur le système d’appel d’urgence eCall. Les questions de respect de la vie privée sont suivies de près par la CNIL qui a soumis en mai 2025 un projet de lignes directrices sur l’utilisation des données de localisation des véhicules connectés ainsi que des recommandations pour le développement d’applications mobiles. Ces données ne couvrent que les modes Véhicules Légers VL et Poids Lourds PL.
Les données FCD représentent un marché mature avec divers cas d’usage et un écosystème de fournisseurs de données et d’outils pour les analyser : producteurs, agrégateurs et revendeurs. Leur taux de pénétration est significatif mais reste limité : au total pour l’ensemble des constructeurs, moins de 10 % du parc contribue aux données FCD disponibles, il est également variable selon les origines-destinations.
Les principaux cas d’usage sont les suivants :
1/ Analyse de la congestion à partir des vitesses et temps de parcours routiers
Le principal cas d’usage est en temps réel, pour l’exploitation du réseau routier et l’information des usagers, mais ces données sont également historisées et utiles pour des analyses.
2/ Estimation des débits
Les FCD peuvent permettre d’estimer les débits de véhicules (VL, PL), typiquement les trafics moyens journaliers annuels à partir du nombre de véhicules tracés sur un tronçon routier, en calant les estimations à partir des données de comptages ponctuels disponibles qui restent indispensables. Plusieurs fournisseurs de données commercialisent des estimations de débits. Le Cerema a estimé les trafics pour l’établissement des cartes de bruit stratégiques, dont une présentation a été faite en juillet 2025.
Le redressement des données présente des difficultés car le parc de véhicules équipés pour la source de données FCD n’est pas nécessairement représentatif de l’ensemble des véhicules (ce sont souvent les véhicules les plus récents). De plus, un véhicule équipé ne sera pas forcement émetteur de trace. Le choix est laissé au conducteur de partager les données de localisation. A cette limite individuelle s’ajoute une limite collective : les tronçons peu fréquentés ne seront pas analysables, le volume de données disponibles étant trop faible.
3/ Analyse des itinéraires et origines-destinations à partir de traces agrégées

Certains fournisseurs de données proposent aussi des outils d’analyse de ce type (chevelus, Origines-Destinations OD), qui permettent aux gestionnaires et autorités organisatrices de mieux comprendre les flux de circulation et d’analyser les déplacements en VP (ou PL).
Là aussi, la difficulté de la représentativité et du redressement est à souligner.
Parce que les données sont anonymisées, les localisations des origines-destinations restent imprécises. Pour l’analyse des longues distances, s’ajoute également la prise en compte des pauses des conducteurs. L’anonymisation des données nécessite un changement récurrent des identifiants. Ainsi, selon les sources de données, chaque véhicule tracé est susceptible de changer d’identifiant toutes les 1/2h à peu près. Par conséquent, les durées des traces individuelles équivalent à la période entre deux renouvellements des identifiants.
Néanmoins, ces données restent prometteuses pour remplacer une collecte traditionnelle d’enquête origines-destinations en bord de route, en particulier lorsqu’elle est physiquement impossible ou dangereuse, sans pour autant bénéficier du même niveau d’informations (notamment absence des caractéristiques socio-démographiques des conducteurs, motifs de déplacements, nombre de passagers, marchandises transportées,…). Des expérimentations sont en cours au Cerema sur ce sujet.
Un autre cas d’usage des données individuelles est de pouvoir accéder aux vitesses individuelles des véhicules sur chaque tronçon routier, ce qui a permis au Cerema d’analyser l’effet de la mise en place d’une limitation de la vitesse à 30 km/h dans le cadre du projet Villes 30 (étude en cours).
4/ Utilisation d’autres Données de localisation/positionnement des véhicules enrichies : les xFCD
Les véhicules sont également sources de données beaucoup plus riches (dites xFCD, pour extended FCD) utilisant les nombreux capteurs embarqués des véhicules. Les données issues de ces capteurs ont un fort intérêt pour les analyses d’accidentologie, des aménagements de voirie, du comportement des véhicules, pour l’entretien routier, mais aussi pour les analyses des déplacements (par exemple le comptage des passagers, très intéressant pour les études relatives au covoiturage et aux voies réservées VR2+).
Données de téléphonie mobile (Floating Mobile Data, FMD) :

Les données Floating Mobile Data sont des données d’estimation de localisation des possesseurs de téléphone mobile que peuvent produire les opérateurs de réseaux de téléphonie mobile à partir des données d’exploitation (suivi de la signalisation et des évènements recensés par les antennes fixes). Le niveau de précision est loin d’atteindre celui des Floating Car Data, mais s’améliore avec les générations de systèmes : avec les techniques utilisées, il s’agit plutôt de suivre dans le temps la présence des téléphones dans chaque cellule du réseau. L’unique fournisseur de cette donnée en France en 2025 est Orange (offre de service Flux Vision).
La donnée est fournie sous 2 formes qui correspondent à deux cas d’usage :
1/ Variations relatives de la population présente sur un territoire à un moment donné ou entre deux territoires
C’est le principal cas d’usage, surtout déployé dans d’autres domaines : commerce, tourisme, sécurité (suivi en temps réel de grands événements comme les JO, Covid...). Cette donnée intéresse bien sûr les instituts nationaux de statistique (l’Insee en France) qui travaillent au niveau européen pour harmoniser les méthodes et les données.
La donnée dépend de la part de marché de l’opérateur qui la fournit (environ 30 % en France pour Orange), elle permet aussi d’identifier des téléphones étrangers (quand l’opérateur a un accord d’itinérance – roaming - avec l’opérateur fournisseur), avec des difficultés aux frontières du pays. Elle présente aussi des difficultés de redressement (le domicile du possesseur du téléphone n’est pas connu, rendant ainsi difficile le redressement à partir des données du recensement par exemple), mais la représentativité est bonne et permet de suivre les évolutions dans le temps selon l’heure de la journée ou le jour dans l’année.
Cette donnée ne permet toutefois pas de connaître les déplacements afférents aux personnes.
2/ Estimation des flux de personnes à grande échelle
Ces données peuvent également être traitées pour estimer des flux de personnes entre zones, avec une précision spatiale qui dépend de la densité d’antennes fixes (plus élevée avec la 5G que la 4G). Actuellement, elles ne permettent pas de distinguer finement les modes de transport urbains (cela reste un sujet de recherche) mais peuvent identifier les macro-modes ferroviaire/routier/aérien en inter-urbain.
Données des applications mobiles

Les applications fonctionnant sur les téléphones mobiles sont aussi des sources de données. Le terme "SDK" est souvent utilisé pour désigner ces données, car elles sont fournies via un "kit de développement logiciel" (software development kit) par des acteurs intermédiaires et utilisé par le développeur de l’application, ce qui facilite leur recueil.
Le recueil de traces peut être indirect, via des éditeurs d’applications diverses (météo, jeux, info,…). Les données sont ensuite revendues par des agrégateurs. Cette donnée est d’une qualité très variable par nature car elle provient d’applications très hétérogènes, utilisées de manière épisodique par les utilisateurs, sur lesquels on ne dispose d’aucune information. Même si potentiellement elle représente beaucoup d’utilisateurs et fournit des positions précises, il est très difficile d’évaluer son niveau de représentativité et donc à redresser. Elle n’est à ce jour que très peu utilisée pour des études de mobilité, en tout cas seule. Actuellement, des projets de recherche investiguent la question et le Cerema travaillera à fournir des préconisations et le domaine d’emploi de ces données.
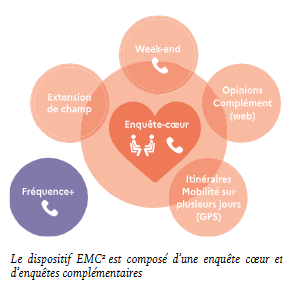 Le recueil peut également se faire via des applications dédiées au recueil de traces de mobilité (avec le consentement actif de l’utilisateur bien sûr) : des expérimentations sont en cours dans le cadre d’une option GPS de l’EMC² (téléchargement via un enquêté de l’EMC² d’une application GPS pouvant être associée à des algorithmes de reconnaissance des modes et motifs par apprentissage, des processus de validation et un questionnaire d’identification des caractéristiques socio-démographiques), dans l’objectif de connaître plus précisément les itinéraires, ainsi que la mobilité de l’enquêté sur les sept jours de la semaine. Il convient de soigner le recrutement pour motiver l’enquêté, l’encadrer et lever les biais de sélections inhérents à cette collecte (personnes plus diplômées,...).
Le recueil peut également se faire via des applications dédiées au recueil de traces de mobilité (avec le consentement actif de l’utilisateur bien sûr) : des expérimentations sont en cours dans le cadre d’une option GPS de l’EMC² (téléchargement via un enquêté de l’EMC² d’une application GPS pouvant être associée à des algorithmes de reconnaissance des modes et motifs par apprentissage, des processus de validation et un questionnaire d’identification des caractéristiques socio-démographiques), dans l’objectif de connaître plus précisément les itinéraires, ainsi que la mobilité de l’enquêté sur les sept jours de la semaine. Il convient de soigner le recrutement pour motiver l’enquêté, l’encadrer et lever les biais de sélections inhérents à cette collecte (personnes plus diplômées,...).
On peut aussi citer des expérimentations en région parisienne (IPR avec des petits enregistreurs GPS dédiés, IDFM, étude pour la DREIAT) et une utilisation avec des applications de "marketing mobilité" (type moovance ou weflo en France).
Conclusions et perspectives
L’analyse des mobilités n’est pas le principal marché pour ces données massives : pour les FCD, c’est plutôt la sécurité, l’information temps réel, la gestion du véhicule ou les services aux conducteurs ; pour les SDK, la publicité et le géomarketing ; pour les FMD, le tourisme, le commerce, la sécurité publique.... On constate toutefois un usage croissant de ces données dans l’analyse des mobilités.
Pour beaucoup de cas d’usage (mais pas tous), il est nécessaire de redresser (extrapoler à la population-cible) les données pour rendre compte de l’ensemble de la population, en s’appuyant sur des données traditionnelles dites de référence (comptages, enquêtes OD, EMC²,…) bénéficiant d’un standard. En effet, ces données massives peuvent présenter un biais de sélection, en excluant une partie de la population-cible (absence d’anciens véhicules représentant une part importante du parc français actuel, extinction de la géolocalisation du téléphone ou du téléphone lui-même,…) ou au contraire en la surestimant (confusion des VL et des PL, double équipements,…), ou encore en ne mesurant pas l’objet attendu (par exemple une présence, mais pas le déplacement). Ce redressement doit être transparent.
L’accès spatio-temporel aux données permettant une mesure ponctuelle ou une évolution reste très dépendante de l’historique des données, souvent limité au court-moyen terme. Par ailleurs, cette donnée reste très évolutive, avec des technologies variables (évolutions des véhicules et aides à la conduite, des smartphones,…) et des populations générant les signaux inégales dans le temps. Des analyses relatives à des évolutions doivent ainsi prendre en compte ces facteurs.
Par ailleurs, les informations fournies restent limitées : pas de connaissance des motifs, des caractéristiques socio-démographiques des personnes à l’origine de la donnée, voire des modes, faibles connaissance et précision des déplacements, et notamment des origines-destinations.
Un cas d’usage très attendu est de pouvoir extrapoler à d’autres périodes de l’année les résultats des enquêtes et estimer les évolutions de la mobilité entre 2 enquêtes. Des recherches académiques et des entreprises innovantes travaillent sur ce sujet, avec des résultats intéressants, même si à ce jour, il n’existe pas encore de méthode de référence, validée statistiquement.
 Pour la connaissance des déplacements quotidiens des résidents d’un territoire, les enquêtes EMC² - Enquête de Mobilité Certifiée Cerema restent des sources de données fondamentales : elles sont multimodales par construction, permettent de suivre l’enchaînement des déplacements, de recueillir des données descriptives des individus enquêtés et des motifs des déplacements, et alimentent les modèles de déplacements qui captent bien les paramètres de comportement. Également, elles présentent l’avantage que l’échantillonnage est maîtrisé, alors que les fournisseurs de sources de données massives ont leurs propres sources, dont on ne peut pas forcément apprécier le niveau de représentativité.
Pour la connaissance des déplacements quotidiens des résidents d’un territoire, les enquêtes EMC² - Enquête de Mobilité Certifiée Cerema restent des sources de données fondamentales : elles sont multimodales par construction, permettent de suivre l’enchaînement des déplacements, de recueillir des données descriptives des individus enquêtés et des motifs des déplacements, et alimentent les modèles de déplacements qui captent bien les paramètres de comportement. Également, elles présentent l’avantage que l’échantillonnage est maîtrisé, alors que les fournisseurs de sources de données massives ont leurs propres sources, dont on ne peut pas forcément apprécier le niveau de représentativité.
Des expérimentations sont en cours afin d’appréhender l’usage possible de données FMD (et plus généralement l’usage d’une fusion de données) pour actualiser certains indicateurs de la mobilité de l’EMC².
Compte tenu des rapides progrès des méthodes d’apprentissage machine, la piste la plus prometteuse est sans doute de pouvoir utiliser l’information venant de plusieurs sources de données (fusion de données FMD, FCD, mais aussi billettique, SDK, etc.) pour effectuer des estimations plus robustes, toujours en se calant sur des sources de données de références, comptages et enquêtes.
Données massives et données plus traditionnelles demeurent ainsi deux sources de données bien complémentaires.
Dans tous les cas, il est important de comprendre comment ces données sont produites, leurs limites et leurs biais. Si les différentes sources de données massives sont à ce jour bien documentées au travers diverses expérimentations, leur mise en œuvre pratique à grande échelle reste encore à consolider et nécessite une bonne expertise métier sur la mobilité.
Une communauté "Données de mobilité" sur la plateforme collaborative Expertises.territoires :

1/ S'inscrire sur Expertises.territoires